CellStrat Gen AI Course Class 6 - LLM Appl Devl with LangChain and LlamaIndex
B Banik
10:11
What happens to token size everytime passing chat history
Indrajit CS
10:12
@Banik
LLMs rely solely on the information provided in the current prompt to generate a response.
This means that every time you interact with an LLM, it treats the prompt (including the chat history) as a fresh input.
Since the entire chat history needs to be included in the prompt for context, the total token size increases with every new message.
This can become a concern if your conversations tend to be lengthy, as exceeding the maximum token limit might prevent the LLM from processing the entire prompt.
Sudhakar Reddy
10:16
this is a UI but in case I want to use the same during my application development can I do the same with python apis
B Banik
10:16
Thanks Indrajit Yes concern is exceeding max token size and we had similar use case setting history in context every prompt
Indrajit CS
10:18
@Shudhakar,
While LangChain offers a user interface (UI) for initial exploration and experimentation, the true power lies in its Python API. The UI primarily serves as a convenient starting point, but for production-grade development or building custom applications, the Python API provides the necessary control and flexibility:
Refer to LangChain's comprehensive documentation for detailed instructions, code examples, and explanations of the various APIs: https://www.pinecone.io/learn/series/langchain/langchain-intro/
Sudhakar Reddy
10:18
Thanks @Indrajit its pretty clear now
Gopinath Venkatesan
10:19
wow, extensive documentation by LangChain
Indrajit CS
10:19
Welcome
v balli
10:19
Wahat are columns in the table being shown
Indrajit CS
10:19
Yeah @Gopinath, the documentation is good
Gopinath Venkatesan
10:23
LangChain allows finetuning inside development module?
Indrajit CS
10:24
@Gopi, LangChain doesn't seem to offer a built-in fine-tuning module
Sudhakar Reddy
10:24
When we talked about RAG we mentioned about retrieving from VectorDB.Can we replace VectorDB with Neo4j and still RAG strategy will work?
Indrajit CS
10:25
@Shudhakar ,
Yes, you can replace VectorDB with Neo4j for the Retrieval-Augmented Generation (RAG) strategy and still achieve good results.
pen_spark
Sudhakar Reddy
10:26
ok gr8
Gopinath Venkatesan
10:26
ok, Thanks @Inderjit. I see Agents at the end of the flowchart -- it may provide an alternative way of training.
Indrajit CS
10:27
@Gopi, yes . Agents are great!
The agent interacts with an LLM to understand user instructions, process information, and generate responses or actions.
Agents can store information from past interactions, allowing them to maintain context and personalize responses.
Gopinath Venkatesan
10:27
So once developed via LangChain, the module doesn't learn but fixed App to serve clients
guidePM pp
10:28
what is purpose of indexes
Indrajit CS
10:28
@Gopi, :) yes not yet at least
Gopinath Venkatesan
10:29
domain specific data to LLM
Thanks Inderjit
Indrajit CS
10:29
@guidePM,
Primarily 3 things we
Faster Queries: As mentioned earlier, indexes lead to quicker retrieval of data, enhancing the overall responsiveness of your database application.
Improved Performance: Faster queries translate to a more efficient database system, handling more user requests effectively.
Optimized Resource Utilization: By minimizing the need to scan entire tables, indexes reduce the processing power and memory required for data retrieval, leading to better resource utilization.
prasanna sivaneni
10:29
lang chain agents ,openai tools(function) calling are both are same?
Indrajit CS
10:30
Yes @Prasanna
Function calling is one such method used by agents
Sudhakar Reddy
10:31
Does RAG Mandates use of Langchain
Indrajit CS
10:32
@Shudhakar,
Not really , RAG does not mandate the use of Langchain. RAG is a general technique for improving the performance of large language models (LLMs) by incorporating retrieval of relevant documents before generating a response.
We can use Langcahin, or Llamaindex or DYPY or any other buil in libraries by the LLM providers
Sudhakar Reddy
10:33
ok got it @Indraji
guidePM pp
10:34
Does it support multi tables data ats ame time
B Banik
10:35
can we use Langchain for natural language prompt to convert into set of Application API call similar to generating SQL query
Indrajit CS
10:35
@GuidePM
RAG itself doesn't have an inherent limitation on supporting multi-table data.
The ability to access data from multiple tables depends on the chosen implementation approach.
Langchain offers a user-friendly framework but might require data preprocessing or custom retrievers for multi-table scenarios.
@Banik, yes we can
guidePM pp
10:36
@Indarjit I am talking of Q&A over SQL data. for multi tables
Indrajit CS
10:38
@guidePm,
Yes we can implement it using Langchain but there may not have a ready api as multi-table inference itself is a complex problem
B Banik
10:39
@Indrajit How it knows or translate which application API to call based on prompt e..g. give me all Bond with AAA rating and maturity 10 yrs having yield x% Application have API currently to source data based on user input like above
Amrita Singh
10:40
text2sql will work with RAG on that with LLM's
on structured Databases
v balli
10:42
Could we provide explaination on tables and table relationships as context to the query..
Nimesh Kiran Verma
10:42
Will we get the slides or recording?
If yes how?
Indrajit CS
10:43
@Nimesh if you have subscribed to our course and paid for it you can get the recordings and slides
Milon Mahapatra
10:44
sorry what is the paper name ? can anyone ping here please
guidePM pp
10:44
Indrajit CS
10:44
@Balli,
Providing explanations of tables and their relationships as context to the query can significantly improve the accuracy and efficiency of retrieval in a Retrieval-Augmented Generation (RAG) system.
Imagine a database containing information about bonds:
Tables:
bonds: Stores details about individual bonds (ID, name, issuer, rating, maturity, yield, etc.)
issuers: Stores information about bond issuers (ID, name, country, etc.)
Relationships:
A foreign key relationship might exist between
Mohamed Ashraf
10:44
Structural Embeddings of Tools for Large Language Models
Nimesh Kiran Verma
10:44
Please give me the link for paid course content and registration
Mohamed Ashraf
10:45
Indrajit CS
10:45
Indrajit CS
10:55
In late October 2022, Harrison Chase, working at the machine learning startup Robust Intelligence, created Langchain as an open-source project
Sachin
10:59
Due to an internet issue I am able attend properly. Is the video recording will be made available?
Indrajit CS
11:00
@Sachin
Live Class Link (Open to All) : https://meet.google.com/npd-sxcb-hnt
For recordings can subscribe here.
https://cellstrathub.com/course/gen-ai?cardId=1
kapil
11:01
Indrajit CS
11:03
Good one @Kapil, thanks for sharing.
@Rakesh Live class is free for all. For course recordings and notebooks you can subscribe https://cellstrathub.com/course/gen-ai?cardId=1
Ritesh Gupta
11:11
Is there a github / repo shared for the code shared in the meeting?
Indrajit CS
11:12
@Ritesh , the notebooks are available for the paid subscribers of this course only.
You
11:13
ping the chunkviz.up link pl.
Indrajit CS
11:15


You
11:13
ping the chunkviz.up link pl.
Indrajit CS
11:15
You
11:16
Thanks @Indrajit for sharing
Indrajit CS
11:16
Welcome Rakesh
Sachin
11:16
@Indrajit, could you please send the link. Will the recoredings will be shared in the meetup page?
Sudhakar Reddy
11:17
@Indrajit Are there any recommendations on which LLMs which embeddings(to store in VecorDB) or we can use any embeddings
Indrajit CS
11:17
@Sachin the recordings will be available through google classroom
Sachin
11:18
ok. can i see the previous recirdngs also...
Indrajit CS
11:18
@Shudhakar
If you're using Langchain for your RAG implementation, consider LLMs that have good integration with Langchain. Popular choices include OpenAI's API, Bard (Google AI), and Jurassic-1 Jumbo (AI21 Labs). These LLMs offer functionalities for Langchain to interact with them and leverage their capabilities within your application.
Popular embedding
models are there but it can own embedding modules as well
like
Sudhakar Reddy
11:19
Thanks@Indrajit its very much valuable info to try embeddings for Langchain
Indrajit CS
11:19
Universal Sentence Encoder (USE) from Google AI
Sentence-BERT from SentenceTransformers, Effective for semantic similarity search tasks.
@Sachin yes you can
v balli
11:20
what are limitations
of langchain
Do we have any other tools in the similar space
covering those limitations
Indrajit CS
11:21
@Balli something like
Abstraction Overhead
Limited Control over LLM Reasoning
Challenges with Complex Workflows
Scalability Considerations
Slowness
Llamaindex, DSPY
Paul. B
11:22
During Vector Embedding u r importing some HuggingfaceEmbedding Model explicitly? I thought LKangChain will take care of choosing vector embedding model!!
Indrajit CS
11:22
are osme of the alternatives

ndrajit CS
11:12
@Ritesh , the notebooks are available for the paid subscribers of this course only.
You
11:13
ping the chunkviz.up link pl.
Indrajit CS
11:15
You
11:16
Thanks @Indrajit for sharing
Indrajit CS
11:16
Welcome Rakesh
Sachin
11:16
@Indrajit, could you please send the link. Will the recoredings will be shared in the meetup page?
Sudhakar Reddy
11:17
@Indrajit Are there any recommendations on which LLMs which embeddings(to store in VecorDB) or we can use any embeddings
Indrajit CS
11:17
@Sachin the recordings will be available through google classroom
Sachin
11:18
ok. can i see the previous recirdngs also...
Indrajit CS
11:18
@Shudhakar
If you're using Langchain for your RAG implementation, consider LLMs that have good integration with Langchain. Popular choices include OpenAI's API, Bard (Google AI), and Jurassic-1 Jumbo (AI21 Labs). These LLMs offer functionalities for Langchain to interact with them and leverage their capabilities within your application.
Popular embedding
models are there but it can own embedding modules as well
like
Sudhakar Reddy
11:19
Thanks@Indrajit its very much valuable info to try embeddings for Langchain
Indrajit CS
11:19
Universal Sentence Encoder (USE) from Google AI
Sentence-BERT from SentenceTransformers, Effective for semantic similarity search tasks.
@Sachin yes you can
v balli
11:20
what are limitations
of langchain
Do we have any other tools in the similar space
covering those limitations
Indrajit CS
11:21
@Balli something like
Abstraction Overhead
Limited Control over LLM Reasoning
Challenges with Complex Workflows
Scalability Considerations
Slowness
Llamaindex, DSPY
Paul. B
11:22
During Vector Embedding u r importing some HuggingfaceEmbedding Model explicitly? I thought LKangChain will take care of choosing vector embedding model!!
Indrajit CS
11:22
are osme of the alternatives
prasanna sivaneni
11:23
can we do content extraction of webpage using langchain
Indrajit CS
11:24
@Prasanna yes
guidePM pp
11:26
diffrence between function and tools
LAMA INDEX---
GPT Index got renamed to LAMA INDEX,
Vectore, Tree, list Indexing
It has similar functionality of LangChain
It supports queries, has easy support of evaluation





guidePM pp
11:26
diffrence between function and tools
Indrajit CS
11:29
Functions are primarily used for custom logic and data manipulation within Langchain chains.
Tools are pre-built functionalities provided by Langchain or external libraries. They offer common operations relevant to LLM interactions and application development.
Sudhakar Reddy
11:31
@Indrajit do we have control over the kind of index to be used for storing(e.g TreeIndex,ListIndex etc)
Monimoy Purkayastha
11:31
Does LlamaIndex support Excel data
Indrajit CS
11:32
@Monimoy , yes it does
guidePM pp
11:33
Does Langchain & llmaindex suport streaming data ?
Indrajit CS
11:33
@Sudhakar, yes
guidePM pp
11:33
Thanks .
Paul. B
11:34
In Langchain, they r not mentioning explicitly @ Vector Embedding?
Indrajit CS
11:34
@guidepm,
Not all LLMs inherently support true streaming data in the sense of processing continuous, unbounded data sequences. However, some, like OpenAI's API, offer functionalities that allow for processing data in chunks, which Langchain can leverage for streaming interactions.
Paul. B
11:34
Sorry, in *LLamaIndex
Indrajit CS
11:35
@Paul, the fundamenal flow for RAG is same
guidePM pp
11:36
Thanks Indarjit.So you mean depend on LLM model
Indrajit CS
11:36
yes pretty much
guidePM pp
11:36
Thanks
LAMA INDEX CODE :


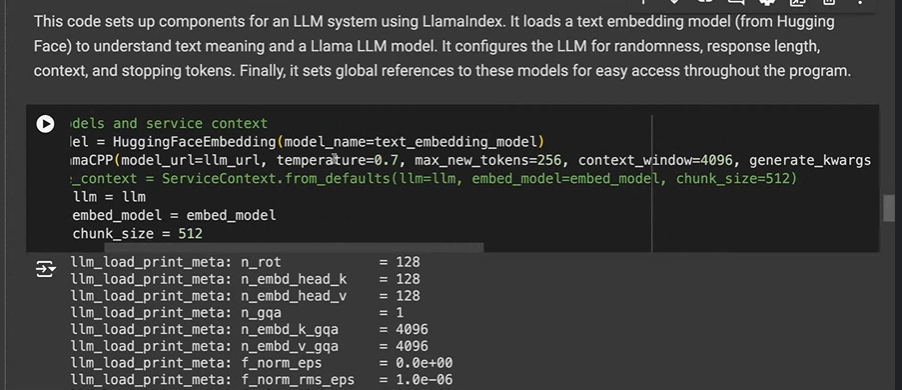


Paul. B
11:34
In Langchain, they r not mentioning explicitly @ Vector Embedding?
Indrajit CS
11:34
@guidepm,
Not all LLMs inherently support true streaming data in the sense of processing continuous, unbounded data sequences. However, some, like OpenAI's API, offer functionalities that allow for processing data in chunks, which Langchain can leverage for streaming interactions.
Paul. B
11:34
Sorry, in *LLamaIndex
Indrajit CS
11:35
@Paul, the fundamenal flow for RAG is same
guidePM pp
11:36
Thanks Indarjit.So you mean depend on LLM model
Indrajit CS
11:36
yes pretty much
guidePM pp
11:36
Thanks
Paul. B
11:39
Thanks @Indrajit. Yeah u r right. Why I asked so because in that diagram, I noticed Llamaindex mentioning as 'Document Nodes' and 'Selector Node' in graph index.
kapil
11:41
@Indrajit - can you pls share Knowledge Graph paper link if possible
Indrajit CS
11:41
@Paul, A Document is a generic container around any data source - for instance, a PDF, an API output, or retrieved data from a database.
A Node represents a "chunk" of a source Document, whether that is a text chunk, an image, or other. Similar to Documents, they contain metadata and relationship information with other nodes.
Indrajit CS
11:43
kapil
11:43
thank you :)
Indrajit CS
11:44
Most Welcome
B Banik
11:47
can you please share git url for both LandChain and LLMAIndex code walkthrough
Indrajit CS
11:48
Sudhakar Reddy
11:48
History is used only for chat usecase
or some other usecase as well
Indrajit CS
11:49
yes
any other uses cases as well
Anand Kumar H
11:49
thanks a lot chandnika , indrajit!
Indrajit CS
11:49
we can use History
Paul. B
11:49
Thank u vm @Indrajit
B Banik
11:49
Thanks Chandrika and Indrajit
Paul. B
11:34
Sorry, in *LLamaIndex
Indrajit CS
11:35
@Paul, the fundamenal flow for RAG is same
guidePM pp
11:36
Thanks Indarjit.So you mean depend on LLM model
Indrajit CS
11:36
yes pretty much
guidePM pp
11:36
Thanks
Paul. B
11:39
Thanks @Indrajit. Yeah u r right. Why I asked so because in that diagram, I noticed Llamaindex mentioning as 'Document Nodes' and 'Selector Node' in graph index.
kapil
11:41
@Indrajit - can you pls share Knowledge Graph paper link if possible
Indrajit CS
11:41
@Paul, A Document is a generic container around any data source - for instance, a PDF, an API output, or retrieved data from a database.
A Node represents a "chunk" of a source Document, whether that is a text chunk, an image, or other. Similar to Documents, they contain metadata and relationship information with other nodes.
Indrajit CS
11:43
kapil
11:43
thank you :)
Indrajit CS
11:44
Most Welcome
B Banik
11:47
can you please share git url for both LandChain and LLMAIndex code walkthrough
Indrajit CS
11:48
Sudhakar Reddy
11:48
History is used only for chat usecase
or some other usecase as well
Indrajit CS
11:49
yes
any other uses cases as well
Anand Kumar H
11:49
thanks a lot chandnika , indrajit!
Indrajit CS
11:49
we can use History
Paul. B
11:49
Thank u vm @Indrajit
B Banik
11:49
Thanks Chandrika and Indrajit
guidePM pp
11:50
Thanks Indrajit & Chandrika
Sudhakar Reddy
11:50
do we have a detailed documentation page for LLamaIndex
like for Langchain
Monimoy Purkayastha
11:50
How stable is LangChain/LlamaIndex currently for developing applications for production
Indrajit CS
11:51
Arbind Choubey
11:51
what are the infrastructure need for deploying the application in production?
Monimoy Purkayastha
11:51
Thanks Indrajit
Paul. B
11:51
For Agentic AI, any better preference is there b/w these or any frameworks so far?
Arbind Choubey
11:53
thanks Indrajit
Anirved Pandey
11:53
just an unrelated question, is it possible to have both image and text as part of the same prompt in the same context?
Paul. B
11:53
Ok. Thank u!
ANKIT SRIVASTAVA
11:54
you can use chatgpt4o
Anirved Pandey
11:54
okay
Mohamed Ashraf
11:54
Aitochain,Gradio
Sudhakar Reddy
11:54
history is used for chat usecase only
Mohamed Ashraf
11:54
hod do you compare with langchain
Autochain,Gradio
Gradio is mainly fromnrnd framework for GUI functionalities I think
&front end
ChainLit
Comments
Post a Comment